Intégrer l'IA dans un produit soulève toujours la même question pratique : quel modèle choisir pour concilier performance, coûts, contrôle des données et déploiement opérationnel ? Dans mes accompagnements, je vois souvent trois grandes familles de choix se dégager : les modèles propriétaires de nouvelle génération (par exemple GPT-4o d'OpenAI), les familles de modèles ouverts performants (Llama d'Meta et ses dérivés), et les alternatives purement open source (Mistral, Falcon, Bloom, etc.). Ici, je partage une grille de lecture pragmatique pour vous aider à décider en fonction de vos contraintes techniques, réglementaires et produit.
Commencer par définir vos besoins réels
Avant de comparer les modèles, posez-vous ces questions concrètes :
- Quel cas d'usage ? (chatbot client, génération de contenu, résumé automatique, recherche sémantique, assistant interne, etc.)
- Quels niveaux de latence et de disponibilité attendez-vous ?
- Quelle sensibilité ont les données traitées (personnelles, financières, santé) ?
- Quel est votre budget d'inférence et de maintien en production ?
- Souhaitez-vous fine-tuner le modèle ou simplement l'adapter via few-shot/prompting ?
Ces éléments orientent immédiatement vers des catégories : si vos données sont sensibles et vous voulez tout garder en interne, l'open source ou l'hébergement dédié sera souvent nécessaire. Si vous préférez une intégration rapide avec haute qualité perçue, les modèles propriétaires cloud-first peuvent être plus adaptés.
GPT-4o : la promesse d'expérience "clé en main"
GPT-4o et ses équivalents propriétaires visent à offrir la meilleure expérience out-of-the-box : compréhension avancée du langage, cohérence, souvent des fonctionnalités multimodales et des API faciles d'usage. Voici les avantages et limites que j'observe :
- Avantages : très bon pour la qualité générative, rapide à intégrer via SDK/API, outils d'alignement et de sécurité (content filters, moderation) souvent fournis.
- Inconvénients : coûts d'utilisation (tokens, requêtes) qui peuvent grimper selon le volume, dépendance à un fournisseur externe, questions de confidentialité et de conformité (sauf si le fournisseur propose des offres "enterprise" on-prem ou dedicated).
- Cas d'usage typiques : assistant client omnicanal, génération de contenu où la qualité et la cohérence priment sur le coût marginal, prototypes rapides pour convaincre des parties prenantes.
Llama et écosystème Meta : compromis entre performance et contrôle
Llama (et ses versions Llama 2/3 ou forks optimisés) offre un bon compromis : modèles puissants, licences plus permissives que certains concurrents, et large adoption dans la communauté. Les options sont variées :
- Hébergement sur cloud public ou privé selon vos contraintes.
- Fine-tuning via LoRA ou adapters pour spécialiser le modèle à votre domaine sans entraîner à grande échelle.
- Meilleure maîtrise des données que sur des APIs propriétaires (si vous hébergez localement).
Points d'attention : l'inférence coûteuse pour les gros modèles, et des optimisations (quantization, Triton, TensorRT, distillation) sont souvent nécessaires pour la production. Il faut aussi prévoir une équipe ML ops capable de gérer ces aspects.
Alternatives open source : liberté et responsabilité
Les alternatives open source comme Mistral, Falcon, Bloom ou les implémentations optimisées par la communauté permettent une flexibilité maximale. Elles sont particulièrement utiles si :
- Vous avez des exigences fortes de confidentialité et de souveraineté des données.
- Vous voulez éviter le vendor lock-in ou contrôler entièrement les coûts à long terme.
- Vous souhaitez intégrer des pipelines de ML customisés (fine-tuning fréquent, intégration avec vos propres embeddings, etc.).
Cependant, il faut accepter la charge opérationnelle : hébergement, scalabilité, sécurité, mises à jour, et responsabilité de la modération et de l'alignement. Pour beaucoup d'équipes produit, cela implique recruter ou former des compétences infra/ML dédiées.
Critères pratiques pour trancher
Voici les critères que je recommande de pondérer selon votre contexte :
- Qualité → GPT-4o et certains modèles propriétaires restent en tête pour la qualité conversationnelle brute.
- Coût → open source + auto-hébergement peut être moins cher à grande échelle, mais nécessite un investissement initial.
- Contrôle & conformité → open source ou offres enterprise dédiées sont préférables pour données sensibles.
- Temps de mise en marché → APIs propriétaires gagnent si vous voulez un MVP en quelques semaines.
- Opérations & maintenance → la charge est plus élevée avec open source (monitoring, sécurité, mises à jour).
Éléments techniques à évaluer
Sur le plan technique, creusez ces sujets :
- Latency & throughput : mesurez la latence sur vos cas réels. Les modèles auto-hébergés peuvent souffrir si non optimisés.
- Fine-tuning vs prompts : fine-tuner (LoRA, PEFT) coûte en ingénierie mais améliore la robustesse sur des tâches spécifiques. Le prompt engineering est rapide mais moins stable.
- Quantization et accélérateurs : 8-bit/4-bit quantization, GPU vs CPU, et solutions comme NVIDIA Triton ou Hugging Face Inference Endpoints peuvent changer la donne coût/perf.
- Vector DB & embeddings : pour la recherche sémantique, combinez embeddings (OpenAI, sentence-transformers, etc.) avec une base de vecteurs (Milvus, Pinecone, Weaviate).
- Test & évaluation : créez des benchmarks internes (qualité, hallucinations, toxicité) et surveillez en production.
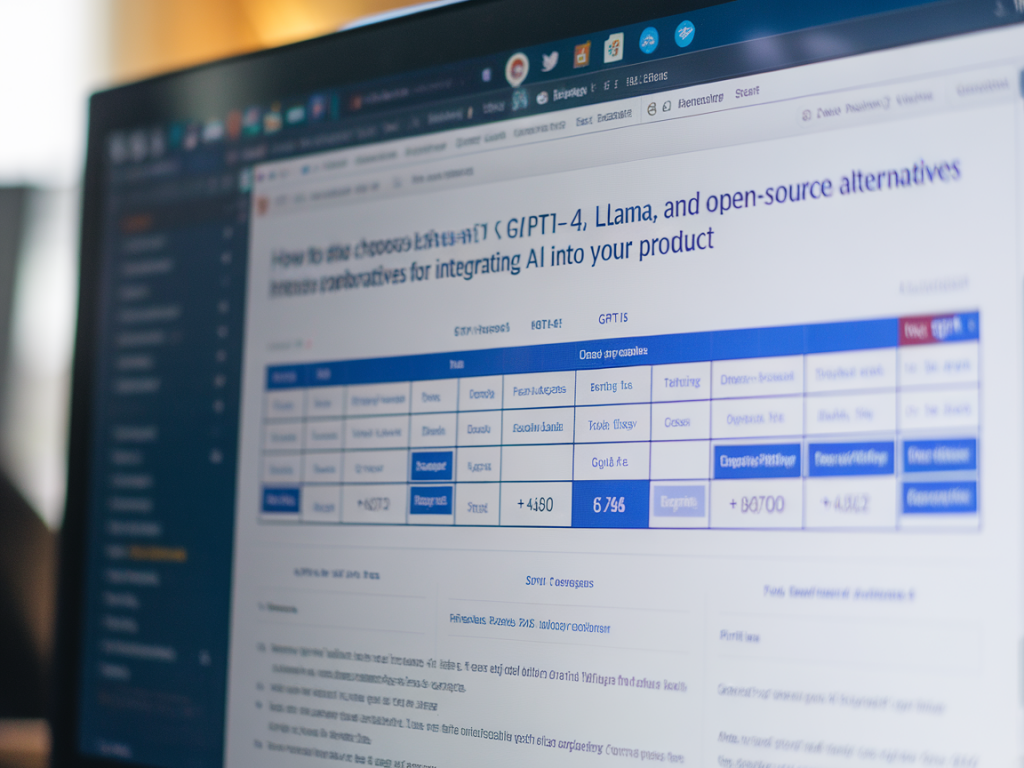
Tableau comparatif synthétique
| Critère | GPT-4o / Proprietary | Llama / Family | Alternatives open source |
|---|---|---|---|
| Qualité linguistique | Très élevée | Élevée | Variable (selon modèle) |
| Contrôle des données | Moyen (sauf offres dédiées) | Bon (si hébergé) | Excellent (si auto-hébergé) |
| Coût à l'usage | Élevé (usage intensif) | Moyen-élevé (GPU) | Potentiellement faible (mais infra coûteuse) |
| Temps d'intégration | Court | Moyen | Long |
Déploiement et gouvernance — ne négligez pas les processus
Choisir un modèle, c'est aussi définir comment vous le gouvernez : politiques de données, processus de validation des prompts, tests de sécurité, plan de rollback, et monitoring. Mettez en place au minimum :
- Logs structurés des entrées/sorties conservés selon la conformité.
- Tests réguliers pour détecter dérives ou régressions.
- Un processus de gestion des hallucinations (escalades humaines, filtres, templates de réponses).
- Plan de mitigation pour les fuites de données ou incidents.
Approche pragmatique que j'utilise avec mes clients
Voici le pattern qui marche le mieux : commencez par un prototype rapide avec une API propriétaire pour valider l'UX et les métriques produit. En parallèle, lancez une expérimentation open source en interne pour évaluer le coût réel d'une autonomie complète. Comparez les deux via des KPIs communs (coût par requête, taux d'erreur/hallucination, latence, NPS utilisateur) et choisissez la voie à l'échelle selon les résultats et les contraintes réglementaires.
Si vous souhaitez, je peux vous aider à bâtir ce protocole d'évaluation (benchmarks, tests, architecture cible) adapté à votre produit et à vos enjeux. L'important est d'aligner technologie et gouvernance dès les premières décisions — c'est ce qui transforme un projet IA prometteur en une fonctionnalité durable et responsable.